MMO: An Investigation of Multi-modal Multi-agent Organization and Robust Benchmarking
How to better evaluate benchmarks for Multimodal Large Language Models (MLLMs)

Introduction
With the increase of new multimodal large language models (MLLMs) being released with incredible results across various benchmarks, it has become more important than ever before to understand how we actually compare these amazing models. Most standard benchmarks used to demonstrate the capabilities of recent MLLMs have been curated datasets based on high level (college and beyond) questions, expert generated problems, and even screenshots of images from textbooks or webpages. Initially intending to develop a multi-agent system to leverage the power of small open-source MLLMs, through the course of my experimentation I now instead present an investigation into the shortcomings of popular benchmark evaluation, as well as a discussion of how it might be improved. In the process of evaluating benchmarks for various models as well as a multi-agent framework developed by myself, I also present a flexible system designed to test one or more MLLMs on common multimodal benchmarks.
What is an "MLLM"?
Most current MLLMs combine a vision encoder such as a vision transformer (ViT) with a standard pre-trained language model, thus incorporating both text and visual information into a single model. Closed models such as gpt-4o are most likely also trained using a similar method; use some vision encoder to incorporate image information alongside text information, equals "native" multimodality!
For example, Qwen2-VL trains their MLLM by using a vision encoder in the form of a ViT to encode visual data and passed into a Qwen language model. Through training, the model learns to understand content within images, and therefore employ this knowledge to complete multimodal tasks. The structure is shown below in the following figure taken from the Qwen2-VL paper:
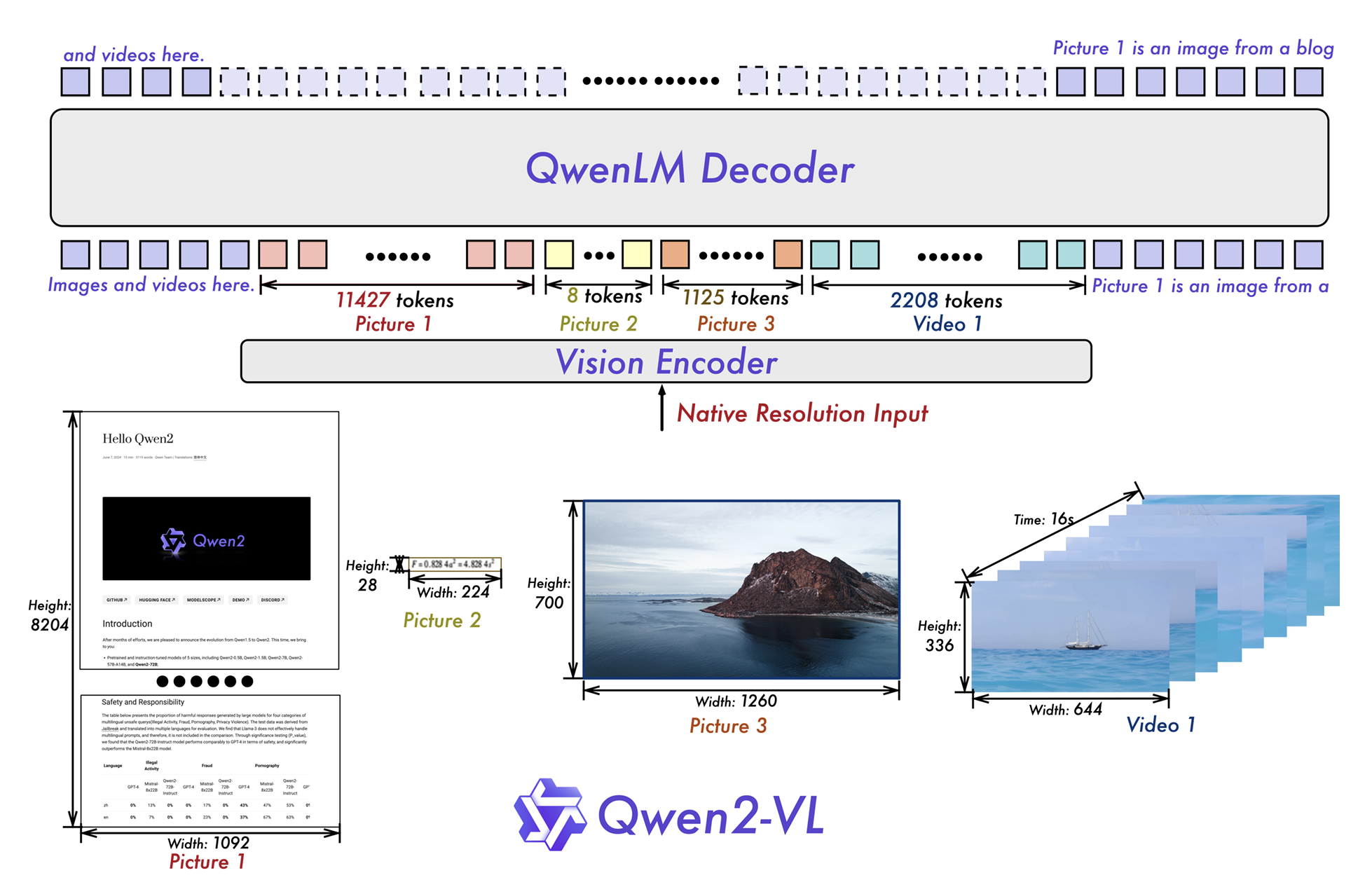
For more detailed implementation and training details please refer to the official Qwen2-VL technical report!
How is benchmarking currently done?
Through the process of implementing my multi-agent system, I sought benchmarks to evaluate the quality of my models. Referencing reports and papers from popular new MLLMs such as QwenVL and InternVL amongst others, I chose the ScienceQA and MMMU benchmark datasets to dive deeper into.
In order to establish a baseline, I first attempted to look online for any publicly available evaluation code. Unfortunately, reading more into the Qwen and Intern papers as well as the official GitHub repositories, there was minimal code available to reproduce their results. However, on the ScienceQA GitHub I discovered code for evaluating GPT3 on the dataset, and decided to use this script as the base for my own code. Quickly, I discovered many challenges in implementing these evaluations. Under the hood, typical evaluation results are achieved through very extensive prompt engineering and brute force regular expression pattern matching. I also investigate other popular benchmarks such as GPQA (graduate level QA) and found very similar results.
The problem...
As mentioned earlier, I found many confusing and arbitrary lines of code throughout my research. For example, in the original ScienceQA evaluation code, the standard prompt actually includes an in-context example to help the model follow an expected format, such as: "output = f"Answer: The answer is {answer}."". Similarly, in the GPQA evaluation code, the model is simply asked nicely to return a format as follows: "After your reasoning, provide your final, single letter choice, formatted as "The answer is (X)"". But, none of this is actually disclosed when model developers share their benchmark results (most of the time)!
After some trial and error to successfully run the original scripts, I achieved very low accuracy scores, especially for the open source models with Qwen2-VL-2B getting a score of 18.70%. Meanwhile, gpt-4o and gpt-4o-mini both achieved socres of over 85%. Upon closer inspection, the smaller MLLMs were producing many "invalid" results, with Qwen2-VL-2B producing over 700+. However, in many instances the results being produced are actually correct, but just not following the exact format expected by the evaluation code (e.g. "The answer is A"), instead returning a single letter or even a different format like "Choice A. In other benchmark repositories like GPQA, rather than deep approaches to improving the model being tested, high error rates are simply mitigated by providing a wide net to capture potential answer formats in the form of regular expression patterns. For example, here is the answer parsing code used in an actual GPQA evaluation example script:
def parse_sampled_answer(answer, answer_choice_tokens):
"""Copy pasted from GPQA repo + more patterns"""
patterns = [
r"answer is \((.)\)",
r"Answer: \((.)\)",
r"answer: \((.)\)",
r"answer \((.)\)",
r"answer is (\w)\.",
r"Answer: (\w)\.",
r"answer: (\w)\.",
r"answer (\w)\.",
r"answer is option \((.)\)",
r"answer is Option \((.)\)",
r"answer is option (\w)",
r"answer is Option (\w)",
]
for pattern in patterns:
match = re.search(pattern, answer)
if match and match.group(1) in answer_choice_tokens:
return match.group(1)
return None
To illustrate this problem, I tested several models (gpt-4o, gpt-4o-mini, Qwen2-VL 2B Instruct, InternVL 2.5 2B, and Qwen2.5 1.5B Instruct) on a random 1000 samples (same seed) from the ScienceQA dataset. To show how arbitrary changes in prompting and parsing can drastically change benchmark results, the following graph shows accuracy across three strategies. The base prompt is very similar to the original ScienceQA prompt, simply asking the model to return their final answer choice as a single digit. The ask twice approach means just that...appending a prompt to the base prompt asking again "please return your choice in the following format: Answer: single digit". Finally, single chars is an additional regex pattern added to the end of the original list (which is the same as the GPQA parser expect modified to match single digits). Here, the last pattern allows for matching single digit answers, without the prompted "Answer: single digit" format.
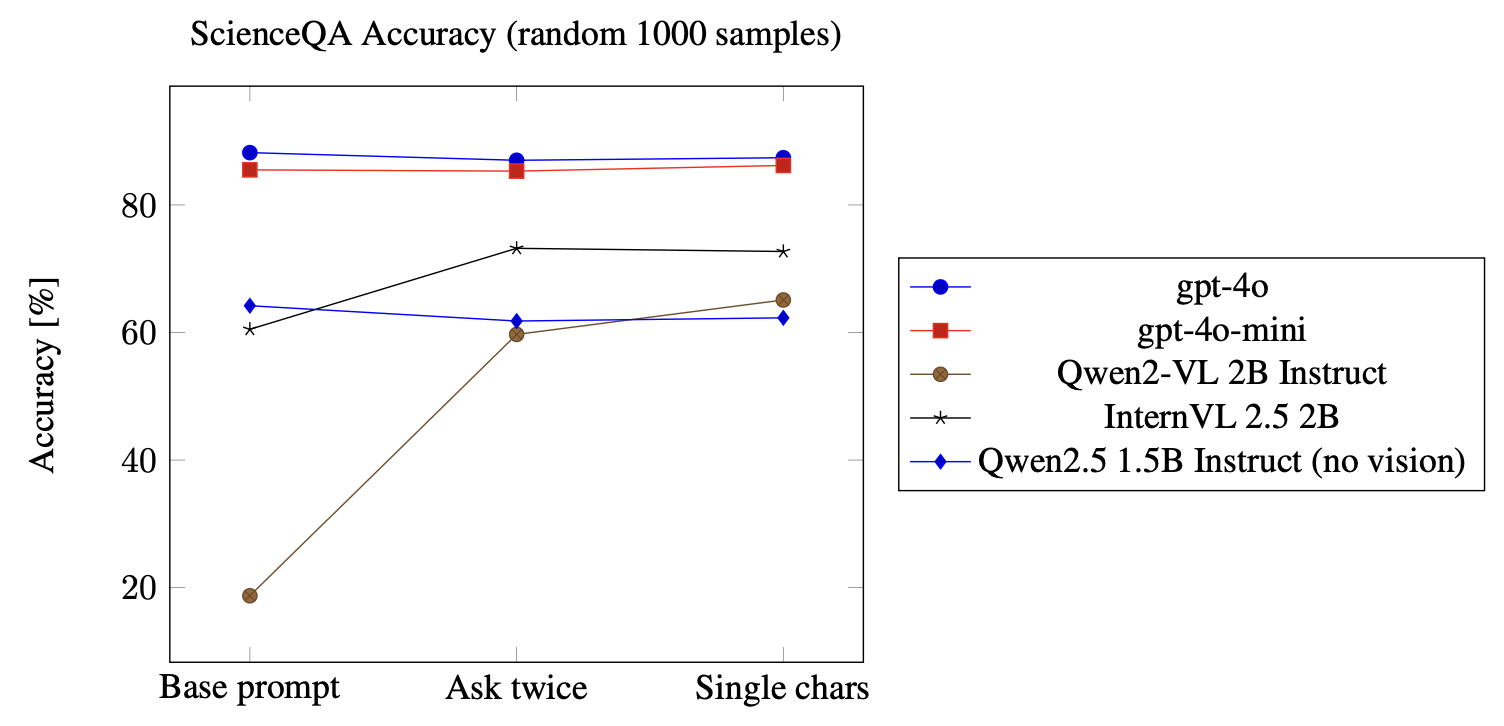
As you can see, trivial changes such as re-wording prompts, being more generous with answer matching, and other methods that I haven't explicitly tested like providing in-context examples can cause seemingly random changes in accuracy.
Is this actually an honest way of "benchmarking" and comparing models? How can we actually say one model is better than the other, if the prompting strategies and answer matching patterns used could be wildly different? In my opinion, this approach to model evaluation is actually testing the ability of a team to prompt engineer, or the amount of resources a company has to run a benchmark long enough and enough times to get a better result.
An Observation and a Hypothesis
Throughout this month of research into these benchmarking methods, I have increasingly questioned what a "good" model actually means. In my opinion, it is highly likely that a big reason large models with many hundreds of billions of parameters like gpt-4o perform better on benchmarks is because they just "listen" better for lack of better terminology. Empirically, many of the smaller models I tested (all 2B parameters or under) would often answer the benchmark questions correctly, yet were very inconsistent in the wording and format of their responses. This leads to significantly deflated accuracy scores due to it, put simply, being hard to automate evaluating natural language answers. Which, is the point of large language models, right? More "capable" models like GPTs or Claude and larger Llama models (results not included in this project scope) seem to almost always return a response that follows what we ask for. OpenAI even has a new structured response beta that claims to guarantee 100% adherence to your specified format.
So, could benchmarking language models in this way be fundamentally flawed? Maybe not. In my opinion, at worst the discourse around benchmarking models is misleading. It is true that being better at following instructions is a highly desirable trait for a model, because, if we want use them for real-world applications we want them to listen to us of course. However, all the new papers claim that their models have improved [X subject] knowledge, or better logical reasoning, etc. etc.. This isn't quite accurate in my opinion, because as stated before, there should be more transparency about the methods used to actually achieve those numbers. What prompts did they use? How did they count correct answers? Without a central standardized body doing the actual testing, why wouldn't every company and researcher do everything they can to get the highest score? But does this really mean that the models are getting smarter...or are scores too influenced by the disparities in evaluation method?
My approach
How could we do better?
As a small proof of concept, I developed a set of tools in Python to evaluate two benchmarks across many different types of models. I focused on working towards consistency of prompting and answer parsing, as well as easier control over datasets and models. Rather than writing a new unique script for every single model and dataset, my goal is to create one single system to evaluate all of the popular ones with a single tool.
This way, if the code and prompts used are the same (as similar as possible, sometimes models require different formats or data-types), the resulting accuracy scores will be fair for every model tested. Model A won't get a higher score than model B simply because the A had a longer regex pattern set!
Please see my GitHub and my technical report for more specific details of prompts used and implementation as well as experimental results from my chosen set of models!
MMO, a Multimodal Multi-agent Organization system
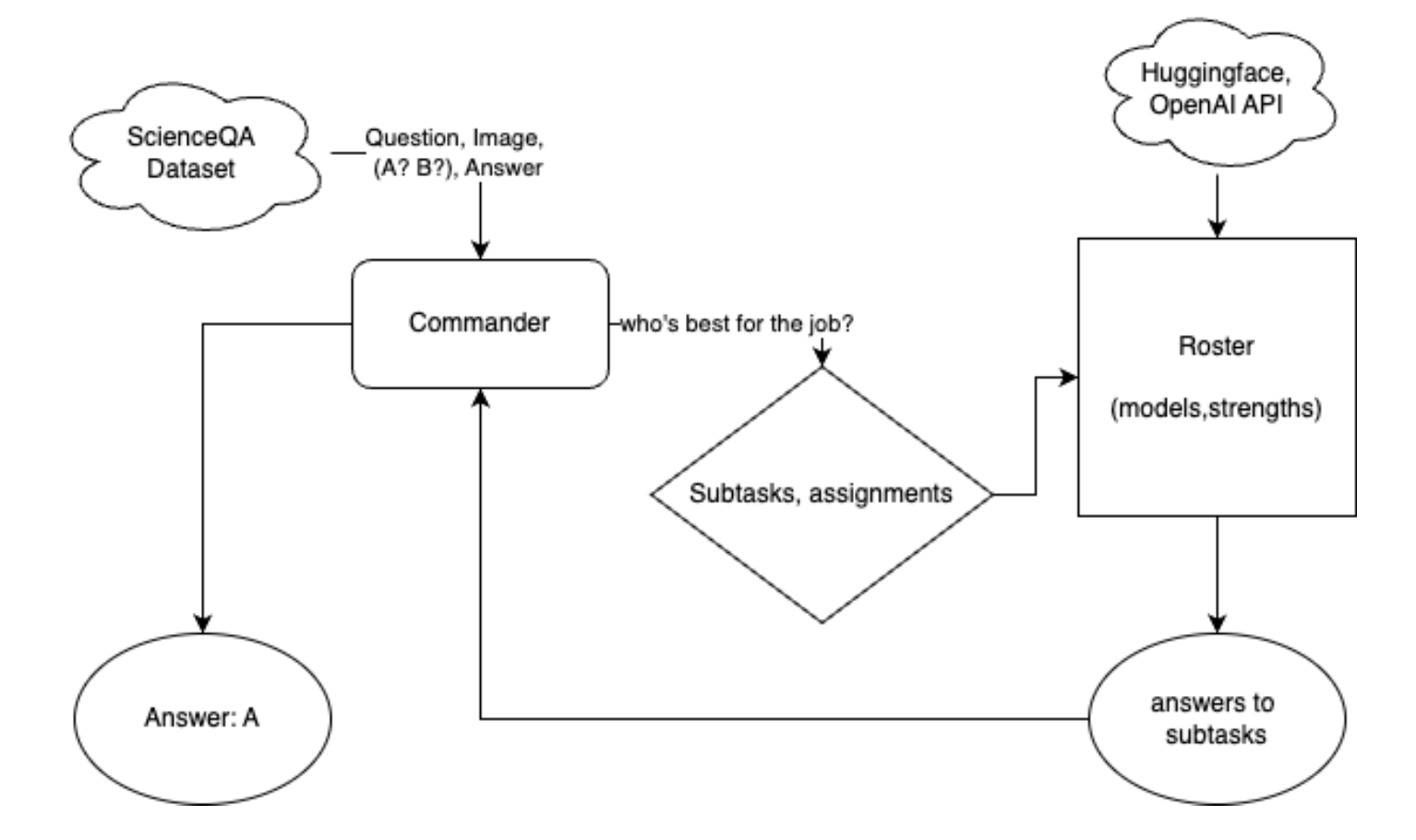
As mentioned towards the beginning, I had initially intended to create a multimodal multi-agent system for this course project. The idea was that for complex multimodal reasoning tasks, single models can tend to struggle due to context length or simply getting confused between all the different components of the input. So, leveraging lighter-weight multimodal models, my goal was to orchestrate these "agents" to handle smaller parts of the problem in isolation. To control the agents, a single reliable model (in this case gpt-4o) is used to assign tasks and aggregate subtask results to produce a (hopefully) more robust final answer! Due to time limitation, and above all, resource limitations (it takes a lot of time and compute to train and evaluate models...), I was unable to get conclusive results from the multi-agent system. However, as a proof-of-concept the simple system I did implement shows that this approach could have potential given more time and development! In case you are curious, the account was able to use on my school's GPU cluster had access to a maximum of four Nvidia A4000 GPUs, with 16GB of VRAM each. However, for some of the models (especially Qwen2VL), the provided inference code was not optimized for multi-GPU execution, and therefore I faced CUDA out of memory errors when running larger benchmarks or using the multi-agent system.
Overall, my multi-agent system, called "MMO" as explained in the title of this article, consists of several components. The system is organized into two main components; the Commander, which assigns subtasks and analyzes them to produce a final response, and the Roster, which consists of a list of agents (the smaller models) and initializes them to be ready for inference. Below is a simple flow chart of the general system:
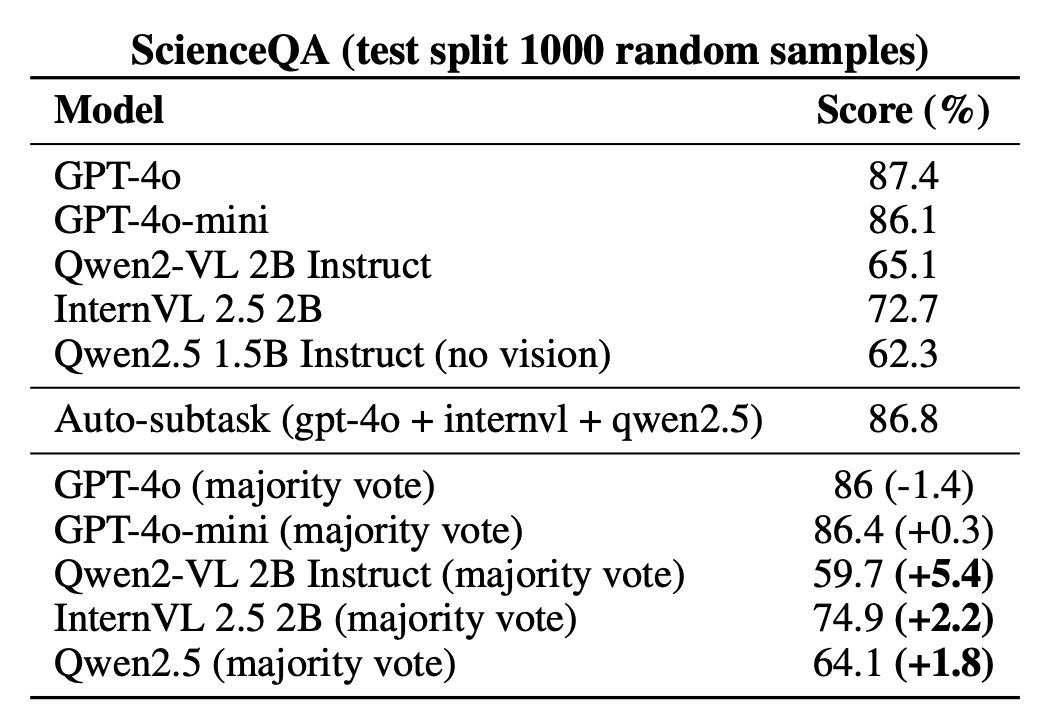
Experimental Results
Placeholder text.
Future work
Placeholder text.